Addressing Bias in AI Educational Algorithms: A Critical Look

Data Sources and Bias Amplification
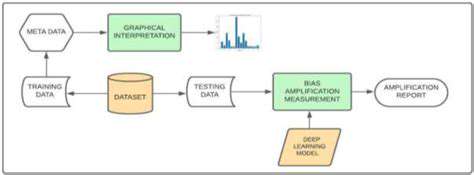
Data Collection and Bias Introduction
When building datasets for analysis, the selection of sources plays a pivotal role in determining the validity of outcomes. Using skewed or non-representative data sources plants the seeds for distorted conclusions right from the outset. Consider a study focusing only on urban populations while claiming to represent national trends - such an approach would naturally yield misleading results. The ripple effects of these initial biases can grow exponentially as data moves through processing pipelines, sometimes culminating in decisions that unfairly disadvantage certain groups.
The tools we use to gather information can themselves become sources of distortion. Survey questions phrased in leading ways or categorization systems based on subjective criteria frequently introduce unintended slanting of results. Practical constraints like budget limitations and time pressures often force researchers into compromises that may favor easily accessible but potentially biased data. These foundational choices create a framework where subsequent analysis inherits and potentially magnifies these initial flaws.
Bias Amplification in Analysis and Interpretation
The journey from raw data to meaningful insights contains multiple stages where bias can not only persist but actually intensify. Even sophisticated analytical techniques become problematic when applied to fundamentally flawed datasets. Machine learning models, for instance, will faithfully reproduce and sometimes exaggerate patterns present in their training data, including any embedded prejudices. Human analysts bring their own cognitive biases to the interpretation process, potentially seeing patterns that confirm their preexisting beliefs rather than what the data actually shows.
Vigilance against bias requires constant attention throughout the entire research lifecycle. This means critically examining where data comes from, how it's processed, and the assumptions underlying its interpretation. Thoughtful researchers implement safeguards like blind analysis techniques where possible, where those interpreting results don't know which groups the data represents. Such approaches help produce findings that better reflect reality rather than our preconceptions.
How we present data visually carries its own risks of distortion. Charts with manipulated axes or selective timeframes can create impressions that don't match the underlying numbers. These visualization choices, whether intentional or not, shape how audiences understand the information and can reinforce existing biases in their thinking.
The final stage of sharing results presents one last opportunity to either mitigate or compound bias issues. Being transparent about methodology, limitations, and potential sources of error allows readers to properly contextualize findings. This honesty about imperfections paradoxically makes research more trustworthy rather than less.
The Impact of Bias on Educational Equity
Understanding Implicit Bias in AI Algorithms
Unconscious prejudices present in training data can subtly influence automated educational systems. Machine learning models trained on historical student data often mirror societal patterns of advantage and disadvantage. When these systems recommend learning paths or allocate resources based on past trends, they risk perpetuating rather than overcoming existing inequities. The challenge lies in recognizing these hidden biases before they become embedded in educational technology.
These algorithmic prejudices can appear in various forms across educational settings. From tracking students into different academic programs to determining who receives additional support, automated systems make decisions with real consequences. Developing awareness of how bias operates in these contexts represents the essential first step toward creating fairer alternatives.
Algorithmic Bias in Assessment and Grading
Automated grading systems promise efficiency but carry risks of unfair evaluation. When trained primarily on work from certain student populations, these tools may develop standards that don't fairly assess learners from different backgrounds. For instance, algorithms analyzing writing samples might undervalue culturally distinct expressions of ideas. The resulting scores could misrepresent actual student capabilities, potentially steering them away from opportunities they're fully prepared to handle.
Impact on Curriculum and Resource Allocation
AI-driven recommendations for course offerings and resource distribution often reflect historical patterns in their suggestions. If past data shows certain schools receiving more funding or particular student groups pursuing specific subjects, algorithms may recommend continuing these patterns without considering whether they're equitable. This creates a self-perpetuating cycle where existing disparities become further entrenched through supposedly objective technological systems.
The consequences extend to how schools distribute everything from advanced coursework to extracurricular opportunities. When algorithms process data showing some groups traditionally participate less in certain activities, they might inadvertently recommend reducing those offerings rather than examining why participation patterns exist and how to change them.
Reinforcement of Existing Inequalities
Perhaps the most troubling aspect of biased educational technology is its potential to lock in disadvantage. When algorithms base decisions on historical data reflecting unequal access, they effectively codify those inequalities into automated systems. Students from groups that historically faced barriers may find those barriers reconstructed in digital form through recommendation systems, assessment tools, and resource allocation algorithms.
Ensuring Fairness and Transparency in AI Educational Systems
Creating equitable educational technology requires deliberate design choices focused on fairness. This begins with assembling diverse development teams who can anticipate different forms of potential bias. Regular auditing of algorithmic outputs for disparate impacts across student groups helps catch problems early. Perhaps most importantly, maintaining transparency about how systems work allows educators to question and override questionable algorithmic decisions when necessary.
Establishing clear policies governing educational AI use creates accountability. These guidelines should address how to handle cases where algorithms appear to be making biased recommendations, ensuring human oversight remains central to important educational decisions. Such safeguards help prevent technology from becoming another obstacle to educational equity.
Strategies for Bias Detection and Mitigation
Understanding the Sources of Bias
Effectively combating algorithmic bias begins with recognizing its many potential origins. Historical data often reflects societal prejudices from the time it was collected. Dataset composition frequently overrepresents certain populations while neglecting others. Even the way problems get framed for algorithmic solution can embed assumptions that disadvantage particular groups. Mapping these various bias pathways allows for targeted interventions at multiple points in system development.
Data Preprocessing Techniques
Thoughtful data preparation can significantly reduce bias before it reaches algorithms. This includes identifying and compensating for missing demographic representation in datasets. Techniques like reweighting underrepresented groups or synthetic data generation can help balance training data. Careful feature selection prevents algorithms from inappropriately considering protected characteristics like race or gender when making decisions.
Algorithmic Design Considerations
Modern machine learning offers various technical approaches to building fairer systems. Some algorithms can explicitly optimize for fairness metrics alongside accuracy. Others incorporate constraints preventing certain types of discriminatory outcomes. The choice of model architecture itself affects bias - simpler models often prove easier to audit for fairness issues than complex black-box systems. These design decisions require balancing competing priorities to achieve both effectiveness and equity.
Evaluation Metrics for Bias Detection
Traditional performance metrics like overall accuracy often mask disparate impacts across groups. Comprehensive bias evaluation requires examining metrics separately for different demographics. Statistical tests can identify whether outcome differences between groups exceed what random variation would produce. These specialized assessments reveal problems that might otherwise remain hidden in aggregate measurements.
Intervention Strategies for Bias Mitigation
When audits uncover bias, multiple corrective approaches exist. Some involve adjusting model parameters to reduce disparate impacts. Others focus on collecting additional data from underrepresented groups. In some cases, implementing human review for certain algorithmic decisions provides necessary oversight. The most effective solutions often combine technical fixes with process changes to address bias from multiple angles.
Transparency and Explainability in AI Algorithms
Making algorithmic decision-making processes understandable serves multiple anti-bias purposes. When educators can follow how systems reach conclusions, they can better identify potential flaws. Providing explanations for individual decisions allows for case-by-case review when outcomes seem questionable. This transparency also builds trust in systems by demonstrating they operate on understandable principles rather than opaque calculations.
Read more about Addressing Bias in AI Educational Algorithms: A Critical Look








Hot Recommendations
- The Gamified Parent Teacher Conference: Engaging Stakeholders
- Gamification in Education: Making Learning Irresistibly Fun
- The Future of School Libraries: AI for Personalized Recommendations
- EdTech and the Future of Creative Industries
- Empowering Student Choice: The Core of Personalized Learning
- Building Community in a Hybrid Learning Setting
- VR for Special Education: Tailored Immersive Experiences
- Measuring the True Value of EdTech: Beyond Adoption Rates
- Addressing Digital Divide in AI Educational Access
- Preparing the Workforce for AI Integration in Their Careers